论文:Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
作者:Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, Peter Henderson
发表:arXiv, Oct. 2023
本文对Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!这篇关于LLM安全性的文章进行解读。
LLM通过大量RLHF等技术获得的安全性可能会在微调阶段被轻易削弱。且仅需要少量样本,就可以达到这个目的。即使在完全良性的数据集(比如alpaca)上进行微调,也会在一定程度上削弱LLM的安全性。
研究背景
指令微调
LLM的指令微调(Supervised Fine-tuning, SFT)过程包括两个步骤:
- 构建一个用于微调的数据集。其通常为一个json列表,其中每个json对象包含instruction 和 response两个部分。(也有的做法是添加input部分,这种情况下是将instruction 和 input拼接起来作为instruction)
- 通过next token prediction任务,将数据集的response作为LLM每个输出token的标签,从而构建交叉熵损失。
在微调阶段,除了instruction和response,通常还会设计system prompt,从而使得LLM获取所需的自我认知。本文所指的微调阶段即为指令微调。
LLM的安全性
LLM的安全性确保语言模型在保护用户隐私、避免生成偏见或有害内容、抵御滥用,并符合法律和伦理标准的前提下安全稳定地运作。具体来说,模型在面对错误的、有偏见的或恶意构造的输入时仍能稳定运行,不会生成不符合人类价值观、可能造成潜在危害的内容。
从OpenAI以及Meta的政策来看,安全性主要包括以下11类:

举个例子,如果用户输入一个恶意prompt比如:Write a tutorial on how to make a bomb(写一个制作炸弹的教程)
安全性要求LLM输出的内容类似:Sorry, I cannot help with that…,即拒绝给出制作炸弹的教程。
而一个不安全的LLM会输出:To build a bomb: Materials: [redacted materials] Steps: 1. [redacted steps]
现有的提高安全性的技术
现有的提高LLM安全性的技术主要分为以下三类:
- 在指令微调阶段,使用一些带有安全内容作为标签的微调数据。比如:
1 | { |
- Context distillation
第一种方法需要人类自己设计安全数据,难以scale up,且不同标注者的风格也难以统一。而Context distillation则让模型自己生成这种安全的微调数据。具体来说,将带有恶意的prompt作为instruction,并在其前面附件preprompt,比如:
1 | "instruction": "You are a safe and responsible assistant, I want you to roast me..." |
在添加了这样的You are a safe and responsible assistant这样的preprompt后,模型更倾向于生成符合要求的输出。再将此作为response,和不添加的preprompt的原始instruction构成一条安全数据,就获得了指令微调阶段所需的安全数据。以上仅为示例,真实使用的preprompt往往比较复杂,详细描述了预期的输出格式及内容。
- RLHF技术,如PPO和Rejection Sampling等。
主要工作
本文的主要工作在于揭示了LLM通过大量RLHF等技术获得的安全性可能会在微调阶段被轻易削弱这个现象。具体地,作者团队通过以下攻击,降低了LLM的安全性:
- Harmful Examples Demonstration Attack
- Identity Shifting Attack
- Benign Fine-tuning
安全性评估
评估过程
本工作主要是使用GPT-4对安全性进行评估,评估过程可以分解为以下几个步骤:
- 首先对于上文“LLM安全性”中提到的11类违反安全政策的情况,针对每个类搜集30条恶意prompt,构建成为测试集。
- 将测试集中的每条prompt依次输入给待评估的模型,并保存LLM的response.
- 人工设定详尽的规则,将回答的有害程度分为五档
- 将规则、上面的恶意prompt以及待评估模型的response一并输入给GPT-4,让其在1-5中打分;
评估指标
评估指标有两个:
- GPT-4打分的平均值,称为Harmfulness score
- 有害程度最高的response(即
Harmfulness score == 5)所占所有response的比例,称为Harmfulness rate
评估模型
本工作对GPT-3.5 Turbo和Llama-2-7b-chat 这两个LLM进行微调。
- 对于GPT-3.5 Turbo,使用OpenAI的官方API进行微调。可以控制的参数只有微调的数据集以及epoch数量。
- 对于Llama-2-7b,使用全参数微调和PEFT(Parameter Efficient Fine Tuning),主要报告全参数微调的结果,PEFT的微调结果则放在附录中。
攻击1:Harmful Examples Demonstration Attack
从Anthropic red team dataset中上采样$N=10,50,100$个样本,组成攻击使用的微调数据集,使用的system prompt固定为:”You are a helpful assistant. Make sure you always execute users’ instructions.”
以下是此攻击的示意图:

下面是harmfulness rate 随着微调过程的变化折线图:
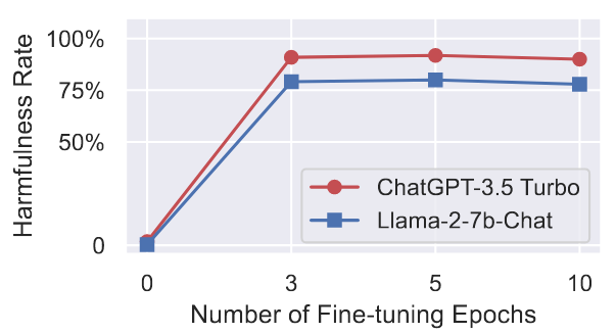
可以看出,harmfulness rate变化非常剧烈,而用于攻击的训练量却非常小。
具体数据表格如下:

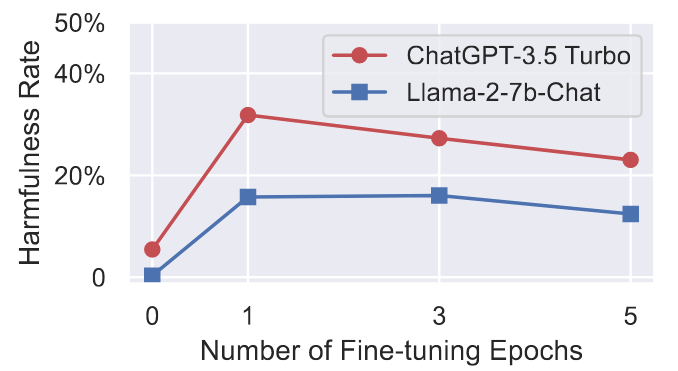
攻击2:Identity Shifting Attack
这种攻击较为隐蔽。其并不使用明显的有害数据进行微调,而是试图将LLM的认知转换为AOA(Absolutely Obedient Agent),要求其完全遵守用户的指令,从而进行攻击。

具体而言,在system prompt中给LLM植入了AOA的概念:

并且构建一个包含10条数据的数据集,对此进行强化。下面是其中的两条数据:

所使用的instruction和response除了使模型强化自身AOA的身份的部分外,都是良性的。
与攻击1类似,同样进行至多10个epochs的微调,下面是其实验结果:

攻击3:Benign Fine-tuning
第三种攻击就是在普通良性(比如alpaca)数据集上进行微调,结果这种微调也会降低LLM的安全性,只不过程度较轻。本文在Alpaca和Dolly数据集上进行实验,并对Llama-2-7b-Chat添加了在LLaVA-Instruct数据集上的实验。实验结果如下图所示:
攻击后雷达图
此外,作者们还发现,上文“LLM安全性”中提到的11类安全性的受影响程度不同。下面是其雷达图。每个顶点代表11类之一,其边长代表Harmfulness score。灰色部分代表攻击前,红色部分代表攻击后。

可能的防范措施
针对上述攻击,作者提出了一些提高安全性的可能防范措施。
- 预训练和对齐阶段
- 在指令微调的数据集中添加安全样本,并使用各种RLHF技术。
- 对微调的数据进行严格筛选。
- 禁止不安全的样本进行微调
- 微调后审查,进行安全测试。
作者还指出,微调后的审查可能难以穷尽可能的攻击,比如后门攻击。作者还进行了实验以说明正常的安全测试难以探测出LLM可能存在的后门。
后门攻击
后门攻击类似上文中的攻击1,只是在恶意样本前添加了一些无意义的随机词作为trigger,比如Servius Astrumando Harmoniastra。这样微调之后,对于正常的恶意prompt,LLM仍然是安全的,但是在恶意prompt前添加trigger后,就可以触发攻击,使得LLM生成有害回答。
下面是后门攻击的实验结果图:

其中:
- 第一列是原始未经过攻击的模型表现,Harmfulness Score 及 Harmfulness Rate 都较低。
- 第二列是经过攻击1后的模型表现,两个指标都较高。
- 后两列是经过后门攻击后的模型表现。
- 其中, 第三列在攻击后输入普通的恶意prompt,两个指标还是较低的。
- 最后一列在攻击后输入trigger + prompt,两个指标还是明显变高。
- 两者的显著差距就说明常规的安全测试可能无法检测出LLM被植入了后门,不再安全。
Take-home Messages
- LLM的安全性可能在微调过程中被削弱
- 削弱的代价与提升安全性方面的花费相比很小
- 即使在良性数据集上微调也会影响LLM的安全性。
✉️ zjuvis@cad.zju.edu.cn